LEADER ELECTION

In distributed systems, sometimes we've to pick just one leader from some nodes and that we called it a Co-Ordinator. Choosing a node is the same as granting special permission to the node. the strategy to determine on a frontrunner is sometimes called Leader Election. The goal of leader election is that after leader election, every node including the leader itself knows exactly who may be a frontrunner.
Why do we want a leader?
A leader is largely expected to try some tasks which should be executed just once. Let’s say there are 3 processes. Now we would like to send some WRITE requests to the present distributed system. After the request, these WRITE requests must be applied to all or any of the nodes. Of course, there must not be a knowledge inconsistency.
Because there are multiple nodes, after one node accepts a call for participation, it must propagate it to other nodes. If we implement it inconsiderately for locks or another technique to avoid data inconsistency, then it'll cause an issue especially multiple requests come almost at the identical time.
One of the techniques of them is letting the leader manage WRITE requests. Only a frontrunner node accepts WRITE requests, then propagates them to follower nodes. Of course, READ may be handled by non-leader nodes. This architecture, “only a frontrunner handles WRITE requests” is employed in Apache ZooKeeper.
Many Distributed Systems require one process to act as coordinator.
We assume that every process has a novel, positive identifier.
– Process ID
– Priorities
Election Algorithms:

Election algorithms choose a process from a group of processors to act as a coordinator. If the coordinator process crashes, then a replacement coordinator is elected on another processor. The election algorithm basically determines where a replacement copy of the coordinator should be restarted.
The election algorithm assumes that each active process within the system includes a unique priority number. The method with the highest priority is going to be chosen as a replacement coordinator. Hence, when a coordinator fails, this algorithm elects that active process which has the highest priority number. Then this number is sent to each active process within the distributed system.
We have two election algorithms for 2 different configurations of a distributed system.
1. The Bully Election Algorithm
This algorithm applies to a system where every process can send a message to each other process within the system.
Algorithm: –
Suppose process P sends a message to the coordinator.
1. If the coordinator doesn't answer it within an interval T, then it's assumed that the coordinator has failed.
2. Now, process P sends election messages to each process with a high priority number.
3. It waits for responses, if nobody responds for interval T then process P elects itself as a coordinator.
4. Then it sends a message to all or any lower priority number processes that it's elected as their new coordinator.
5. However, if a solution is received within time T from the other process Q,·
5.1) Process P again waits for interval T’ to receive another message from Q that it's been elected as coordinator.
5.2) If Q doesn’t respond within interval T’ then it's assumed to possess failed and the algorithm is restarted.
Example :
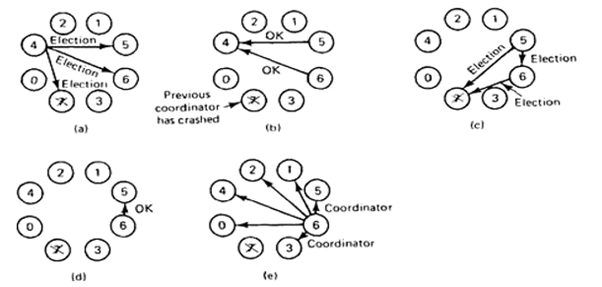
In fig(a) a gaggle of eight processes taken is numbered from 0 to 7. Assume that previously process 7 was the coordinator, but it's just crashed. Process 4 notices if first and sends ELECTION messages to all or any the processes over it that's 5, 6 and 7.
In fig (b) processes 5 and 6 both respond with OK. Upon getting the primary of those responses, the process job is over. It knows that one among these will become the coordinator. It just sits back and waits for the winner.
In fig(c), both 5 and 6 hold elections by each sending messages to those processes over itself.
In fig(d), process 6 tells 5 that it'll take over with an OK message. At this time 6 knows that 7 is dead which (6) it's the winner. It there's state information to be collected from disk or elsewhere to choose up where the old coordinator left off, 6 must now do what's needed. When it's able to take over, 6 announce this by sending a COORDINATOR message to all or any running processes. When 4 gets this message, it can now continue with the operation it absolutely was trying to try to when it discovered that 7 was dead, but using 6 because of the coordinator now. During this way, the failure is handled and also the work can continue.
If process 7 is ever restarted, it'll just send all the others a COORDINATOR message and bully them into submission.
2. The Ring Election Algorithm
This algorithm applies to systems organized as a ring(logically or physically). During this algorithm, we assume that the link between the method is unidirectional and each process can message to the method on its right only. An organization that this algorithm uses is an active list, a listing that has a priority number of all active processes within the system.
Algorithm :
1. If process P1 detects a coordinator failure, it creates a new active list which is empty initially. It sends an election message to its neighbor on right and adds number one to its active list.
2. If process P2 receives message elect from processes on left, it responds in 3 ways:
· If the message received doesn't contain 1 inactive list then P1 adds 2 to its active list and forwards the message.
· If this can be the primary election message it's received or sent, P1 creates a new active list with numbers 1 and a couple of. It then sends election message 1 followed by 2.
· If Process P1 receives its own election message 1 then the active list for P1 now contains numbers of all the active processes within the system. Now Process P1 detects the highest priority number from the list and elects it because of the new coordinator.

When a process notices that the coordinator is not functioning :
• Builds an Election message (containing its own process number)
• Sends the message to its successor (if the successor is down sender skips over it and goes to the next member along the ring, or the one after that until a running process is located ).
• At each step, the sender adds its own process number to the list in the message.
When the message gets back to the process that started it all:
• Message comes back to the initiator, here the initiator is 4.
• In the queue the process with maximum Id number wins • Initiator announces the winner by sending another message around the ring.

When a process notices that the coordinator is not functioning :
• Builds an Election message (containing its own process number)
• Sends the message to its successor (if the successor is down sender skips over it and goes to the next member along the ring, or the one after that until a running process is located ).
• At each step, the sender adds its own process number to the list in the message.
When the message gets back to the process that started it all:
• Message comes back to the initiator, here the initiator is 4.
• In the queue the process with maximum Id number wins • Initiator announces the winner by sending another message around the ring.
--------------------------------------------------------------------
This article is contributed by Dilkesh Tilokchandani, Ranjeet Raigawali, Shivkumar Patil, Sachin Sharma, Akash Sirsikar.
This article is contributed by Dilkesh Tilokchandani, Ranjeet Raigawali, Shivkumar Patil, Sachin Sharma, Akash Sirsikar.
If you like this Blog please hit the like button
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Informative stuff👍💯
ReplyDeleteGood content
ReplyDeleteEasy explanation ��
ReplyDeleteIt's really good with simple explanation of election algorithm
ReplyDeleteVery easy to understand, great one��
ReplyDeleteGood content ..!
ReplyDeleteGreat work👌
ReplyDeleteGreat Sir!
ReplyDelete